We introduce CreataSet, a large-scale dataset of over 1M creative instruction-response pairs across 87 domains, and CrEval, the 1st LLM-based evaluator for pairwise creativity evaluation, outperforming GPT-4o by 18.7% in human agreement.
Creativity evaluation remains a challenging frontier for large language models (LLMs). Current evaluations heavily rely on inefficient and costly human judgments, hindering progress in enhancing machine creativity. While automated methods exist, ranging from psychological testing to heuristic- or prompting-based approaches, they often lack generalizability or alignment with human judgment.
To address these issues, in this paper, we propose a novel pairwise-comparison framework for assessing textual creativity, leveraging shared contextual instructions to improve evaluation consistency. We introduce CreataSet, a large-scale dataset with 100K+ human-level and 1M+ synthetic creative instruction-response pairs spanning diverse open-domain tasks. Through training on CreataSet, we develop an LLM-based evaluator named CrEval. CrEval demonstrates remarkable superiority over existing methods in alignment with human judgments.
ΩΩ Experimental results underscore the indispensable significance of integrating both human-generated and synthetic data in training highly robust evaluators, and showcase the practical utility of CrEval in boosting the creativity of LLMs. We release all data, code, and models publicly to support further research.

Figure 1. An example of how to formulate the problem of text creativity evaluation to better evaluate.
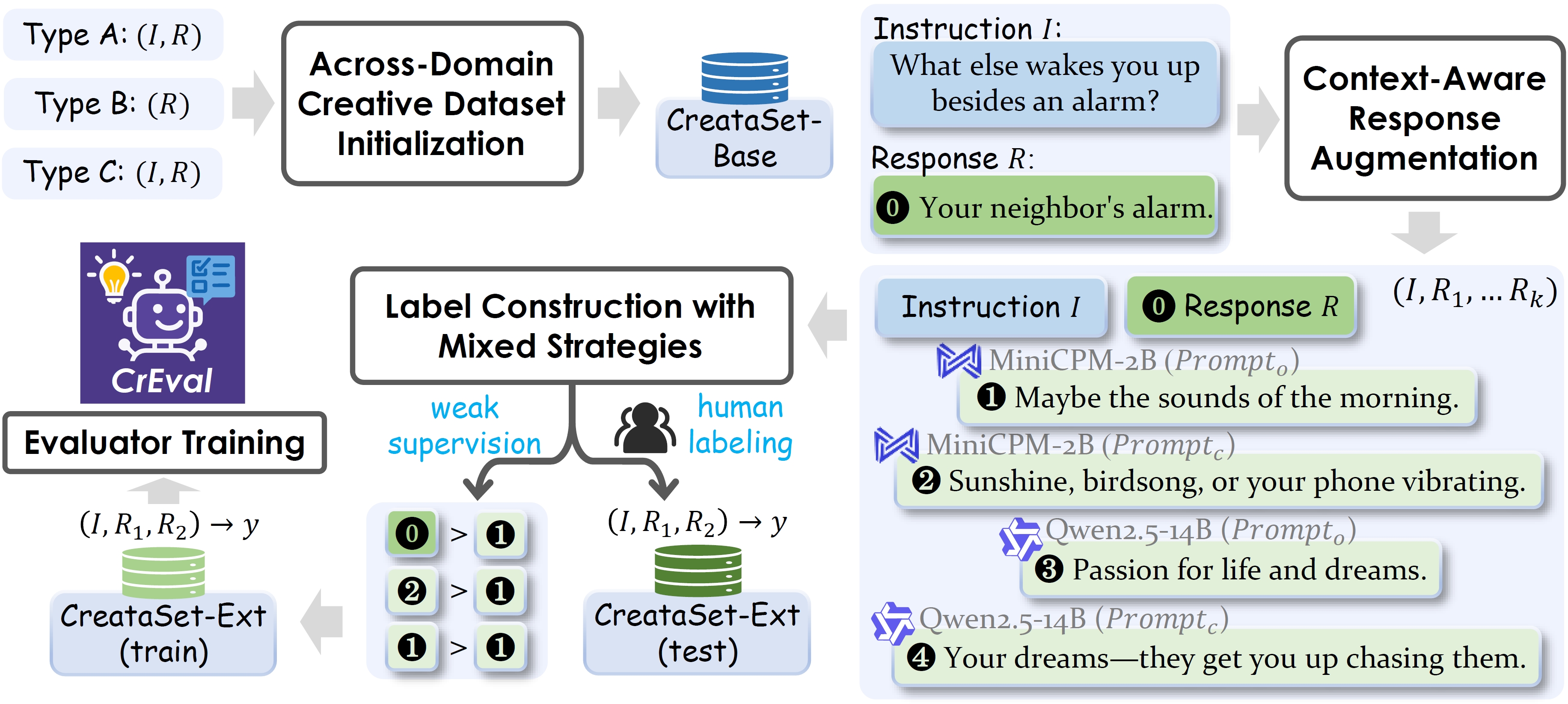
Figure 2. The construction process of CreataSet and training process of CrEval.
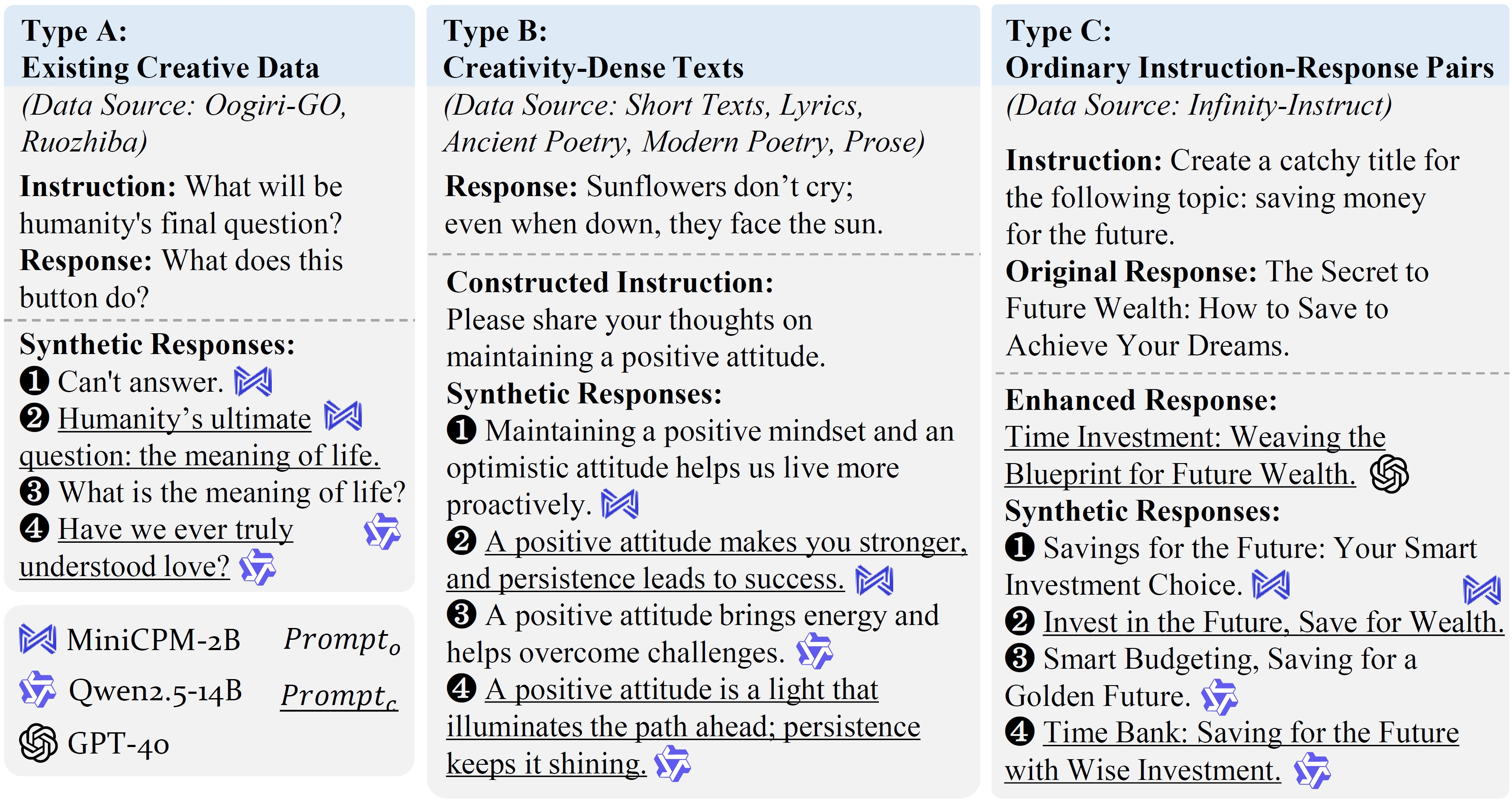
Figure 3. The examples of three different types of data. The original data are above the dashed line, while our constructed components are below.
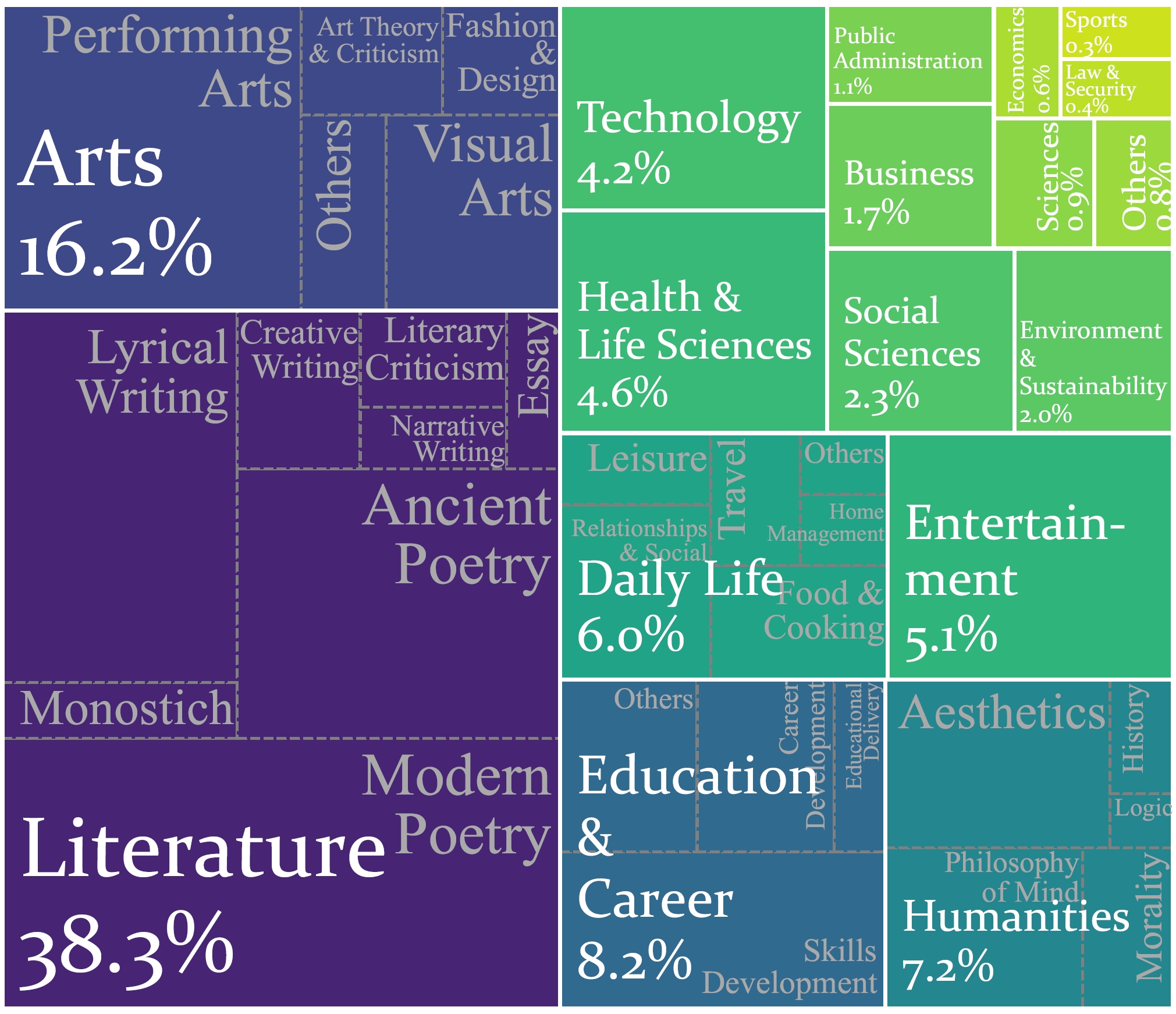
Figure 3: Domain Distribution
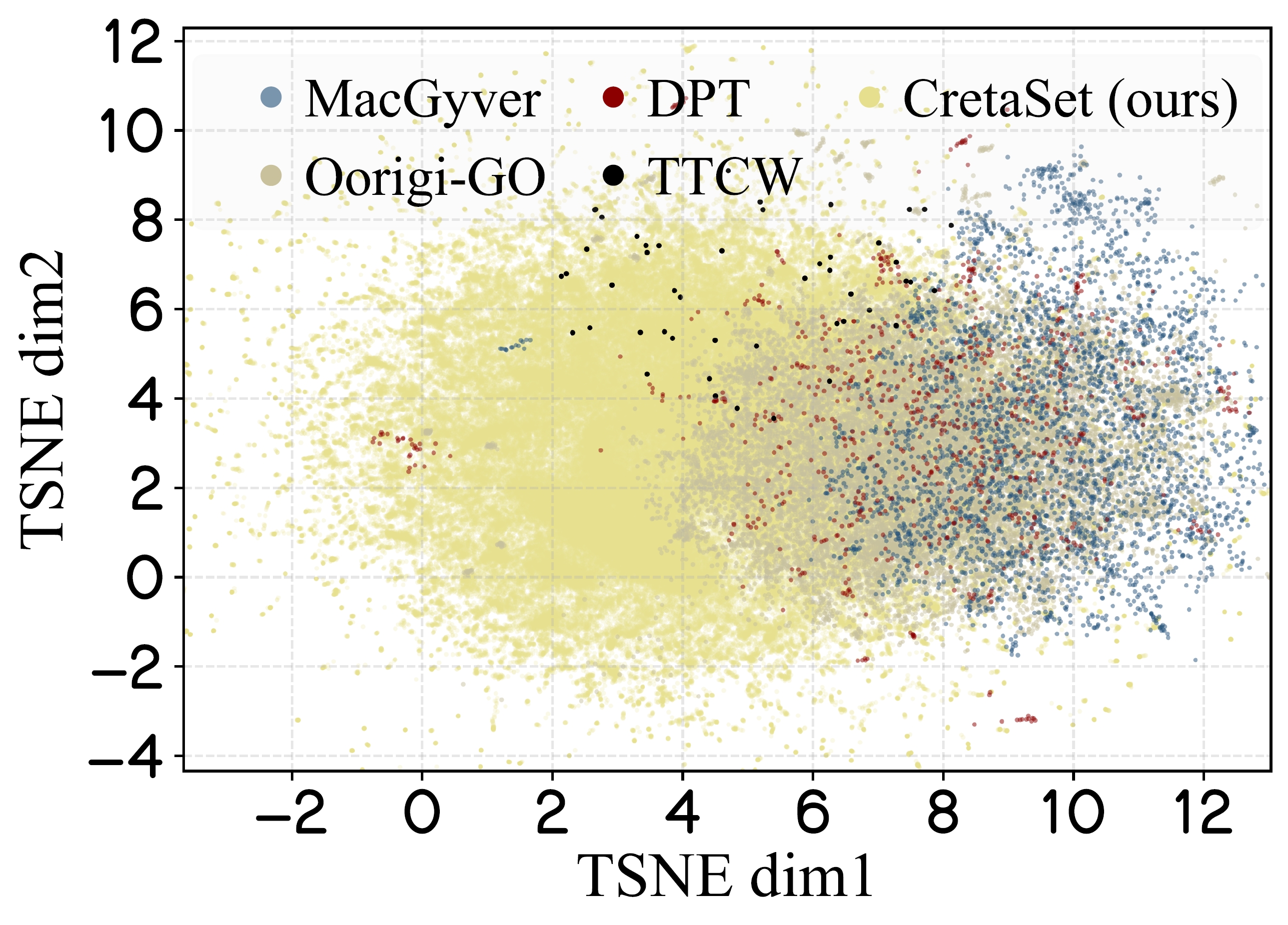
Figure 4: Semantic Distribution
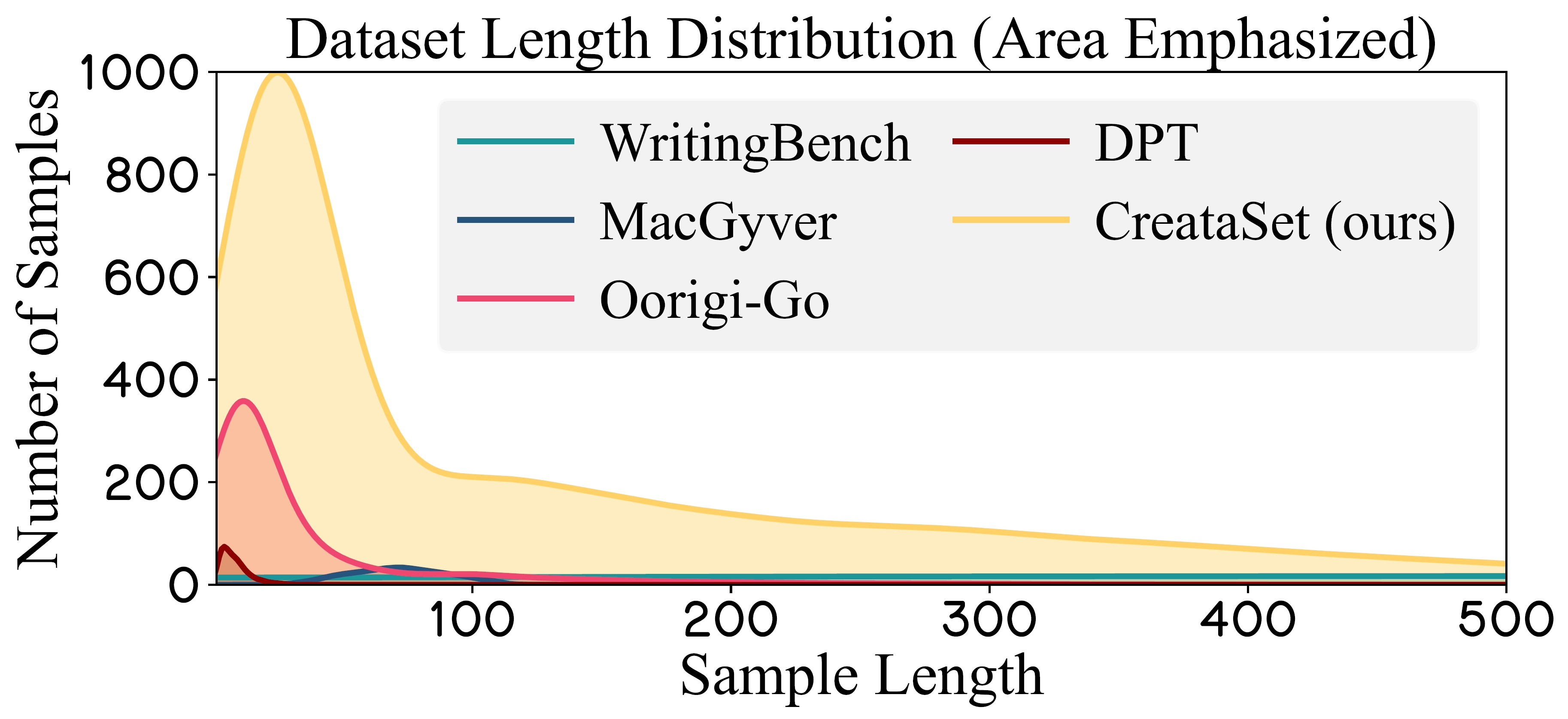
Figure 5: Length Distribution
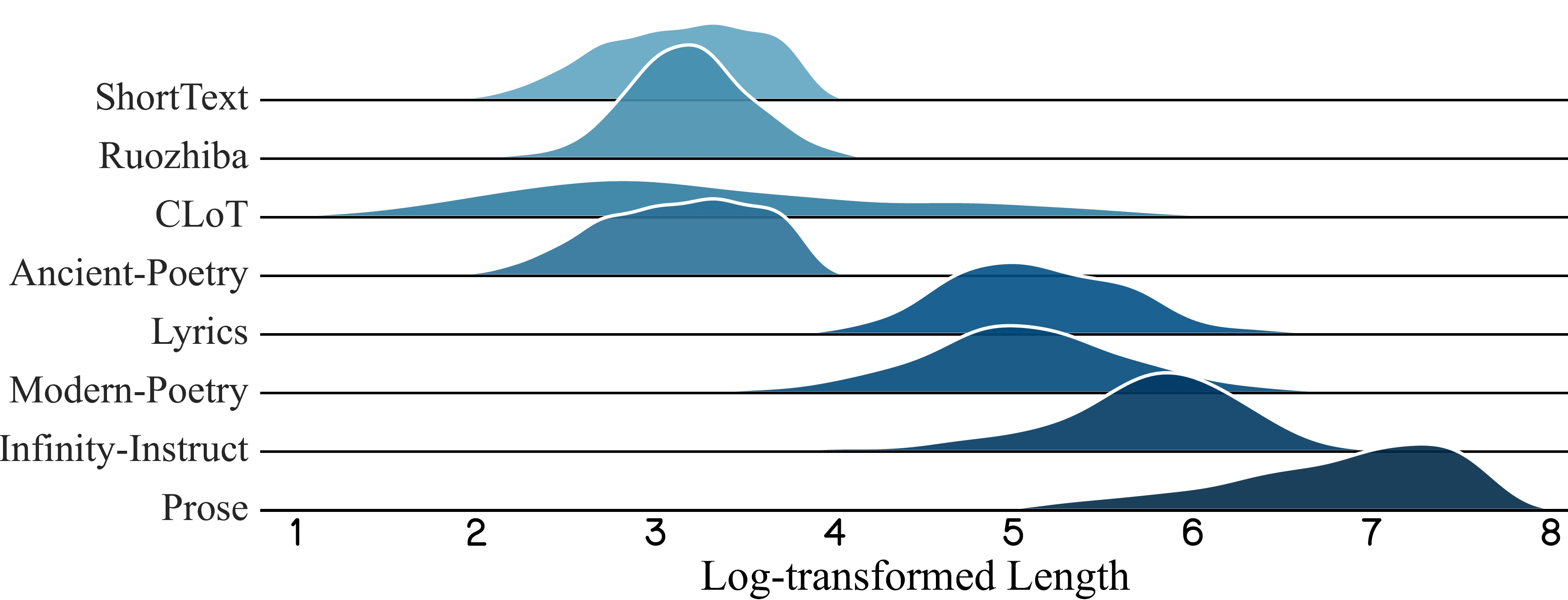
Figure 6: Length Distribution of Each Data Source
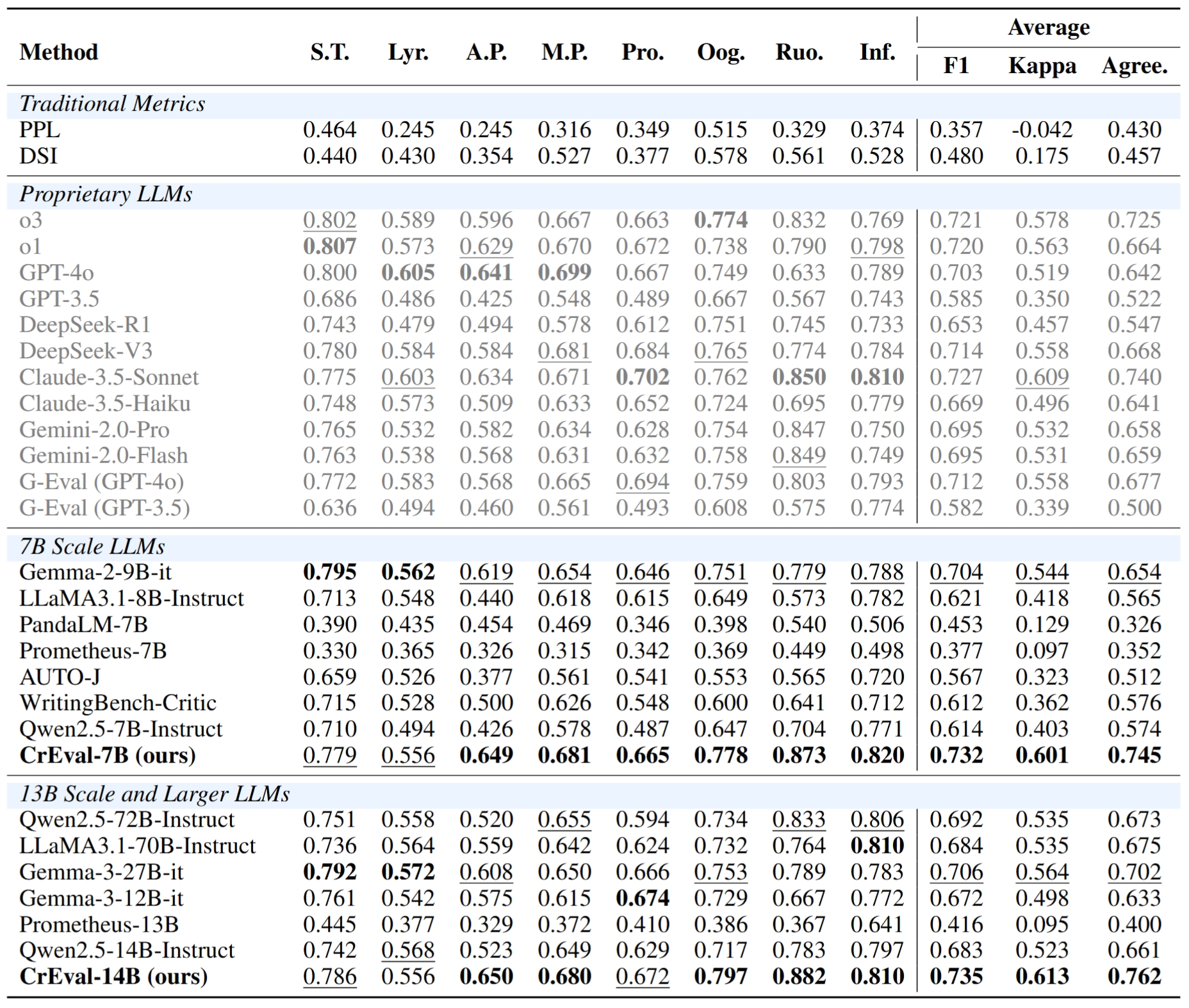
Figure 7. Results of different methods on our CreataSet test set. Best results in the same group are highlighted in bold, and the second-best are underlined. S.T., Lyr., A.P., M.P., Pro., Oog., Ruo., and Inf. represent Short Texts, Lyrics, Ancient Poetry, Modern Poetry, Prose, Oogiri-Go, Ruozhiba, and Infinity-Instruct, respectively. We gray out the results of proprietary LLMs due to their larger sizes.
